
Cara Menghitung Kesalahan Standar Menggunakan Formula

Mereka yang tidak terbiasa dengan seluk-beluk dan kesulitan pengukuran sistemik mungkin tidak terbiasa dengan rutinitas dasar yang digunakan untuk menentukan akurasi. Itu kesalahan standar secara teratur digunakan untuk menentukan akurasi rata-rata bila dibandingkan dengan ukuran sampel yang lebih besar, dan di bawah ini, kami akan menunjukkan kepada Anda cara menghitung kesalahan standar saat menggunakan formula tertentu. Kami juga akan menyertakan tautan ke literatur lebih lanjut tentang latihan statistik umum ini sehingga ketika saatnya diperlukan untuk menggunakannya, Anda akan memiliki banyak pengetahuan untuk melakukannya.
Apakah Anda seorang kutu buku statistik atau seseorang yang hanya mencari pemahaman paling dasar tentang kesalahan standar, baca terus untuk mengetahui lebih lanjut!
Menghitung rata-rata atau median dari sampel bukanlah proses yang sulit. Bergantung pada sifat penelitian, biasanya berarti memilih ukuran sampel tertentu relatif terhadap populasi yang lebih besar dari mana Anda berasal. Setelah melakukannya, langkah selanjutnya dalam proses ini adalah menemukan mean atau median (atau "rata-rata," demi penjelasan singkat kami) dari antara sampel itu. Dengan menggunakan rata-rata itu, Anda dapat membuat beberapa penentuan tentang populasi yang lebih besar tempat Anda memilih sampel.
Namun, seperti yang diketahui oleh siapa pun yang mengenal statistik matematika, proses sederhana semacam itu mungkin tidak memberikan studi yang paling akurat. Lagi pula, bagaimana Anda bisa yakin bahwa sampel yang Anda pilih dengan benar mewakili populasi yang lebih besar? Bagaimana Anda menjelaskan penelitian lain yang serupa yang telah dilakukan dari populasi yang sama, tetapi dengan sampel yang berbeda? Ini semua adalah hal yang perlu diperhitungkan, dan dalam dunia statistik, itu berarti suatu proses diperlukan untuk mengukur akurasi itu.
Rumus yang dirancang untuk kesalahan standar adalah respons terhadap akurasi yang sangat dibutuhkan. Dan meskipun mereka mungkin terlihat cukup rumit – dan mampu menjadi sangat rumit – memahami apa yang mereka gunakan tidak terlalu sulit. Dan karena ukuran sampel selalu akan berbeda dari ukuran populasi yang diwakilinya, perhitungan kesalahan standar diperlukan. setelah semua, jika tidak ada perbedaan antara ukuran sampel dan populasi, tidak akan ada kebutuhan untuk sampel, kan?
Di bawah, kami akan memperkenalkan Anda lebih lanjut tentang metode penghitungan deviasi standar antara sampel dan ukuran populasi. Dan seperti yang dijanjikan, kami akan menyimpulkan pengantar singkat ini untuk formula ini dengan bacaan lebih lanjut untuk berinvestasi, jika Anda tertarik pada studi statistik.
Berarti, Median, Sampel & Populasi
Setiap studi statistik yang dimaksudkan untuk mewakili populasi yang lebih besar akan memerlukan sampel. Dan selama sampel dipilih dengan benar, rata-rata atau median dari sampel itu dapat diterapkan pada populasi dengan tingkat akurasi yang berbeda-beda. Namun, “derajat yang bervariasi” dapat sangat berbeda. Dengan demikian, penyimpangan antara sampel dan populasi hampir sama pentingnya dengan informasi yang diperoleh dari perkiraan rata-rata atau median.
“Tidak ada yang namanya penghasilan median; ada kurva, dan sangat penting di sisi mana Anda berada. Tidak ada yang namanya kelas menengah. Benar-benar menghilang. " – Marc Andreessen
Tanpa metode penentuan penyimpangan, informasi yang diperoleh dari mempelajari sampel menjadi kurang relevan dan berlaku. Faktanya, hampir tidak ada gunanya mencoba menentukan kesalahan standar kecuali Anda memiliki informasi yang diperlukan untuk menentukan standar deviasi. Keduanya terhubung secara rumit, dan bahkan pemeriksaan permukaan dua formula yang akan kita bahas di bawah ini mengungkapkan hal ini – jika Anda tidak tahu parameter sampel populasi yang diwakili, apa gunanya kesalahan standar dari mereka sampel akan menjadi?
Pentingnya Penyimpangan
Penyimpangan akan berubah tergantung pada skenario yang diukur, tetapi ada beberapa hal yang hampir selalu berlaku ketika menentukannya. Ketika melihat satu set data dari sampel yang ditentukan dari populasi yang lebih besar, periksa poin data sehubungan dengan rata-rata yang ditetapkan. Jika mereka menyebar jauh di atas dan di bawah rata-rata (atau rata-rata), Anda melihat penyimpangan yang lebih besar – yang biasanya mewakili studi yang lebih tidak stabil, dalam sampel tertentu. Sebagian besar penelitian yang mengharapkan segala macam hasil akurat memiliki standar deviasi dan kesalahan standar yang relatif rendah – ini mewakili sebagian besar titik data yang dikelompokkan dekat dengan rata-rata. Studi yang memiliki titik data tersebar secara merata di berbagai variabel memiliki kemungkinan lebih kecil untuk menjadi akurat dan biasanya membantu peneliti untuk mengetahui bahwa mereka membutuhkan sudut penyelidikan yang baru.
Jika titik data relatif lebih dekat dengan rata-rata atau rata-rata, nilai deviasi akan lebih kecil juga. Ini akan menjadi penting ketika Anda menghitung kesalahan standar dari serangkaian titik data. Pengukuran penyimpangan ini dalam satu set data tertentu biasanya disebut sebagai standar deviasi.

Kesalahan Standar & Penyimpangan Standar
Meskipun mereka terdengar mirip, kesalahan standar dan standar deviasi sebenarnya adalah dua hal yang berbeda, meskipun keduanya digunakan untuk menentukan jumlah data yang tersebar di seluruh ukuran sampel.
Kesalahan standar menggunakan data dari sampel untuk menentukan penyebaran data itu. Dan standar deviasi memainkan peran penting dalam perhitungan itu karena digunakan untuk menentukan parameter populasi yang diwakili. Satu cocok dengan yang lain, dan dengan demikian, keduanya tidak dapat dipisahkan; jika Anda ingin menghitung kesalahan standar, Anda harus menghitung deviasi standar jika Anda ingin hasil Anda akurat. Tanpa parameter, Anda tidak akan dapat menghitung kesalahan standar sampel dengan tingkat akurasi apa pun.
Menghitung Kesalahan Standar
Selama Anda memiliki informasi yang diperlukan untuk melakukannya, ada rumus yang dapat digunakan untuk menghitung kesalahan standar dalam situasi seperti ini. Kesalahan standar rata-rata (SEM) mewakili standar deviasi dari estimasi rata-rata sampel yang diambil dari keseluruhan, rata-rata populasi yang lebih besar. Seperti yang telah kami jelaskan di atas, ini adalah metode yang akan Anda gunakan untuk menentukan akurasi rata-rata sampel, di samping hubungannya dengan populasi tempat sampel diambil.
Persamaan berikut dan variabel komponennya dijelaskan pada Kalkulator Kesalahan Standar situs, sebagian dari MiniWebTool.
![]()
Dalam rumus di atas, ada beberapa variabel yang perlu Anda ketahui jika ingin menyelesaikan persamaan. Didefinisikan di bawah ini, masing-masing sangat penting:
- SEM: Kesalahan standar rata-rata
- s: Standar deviasi sampel (lihat di bawah)
- n: Jumlah pengamatan sampel
Untuk menghitung standar deviasi sampel, Anda akan memerlukan informasi yang lebih luas dari masing-masing set sampel data yang Anda gunakan. Ini semua harus diambil dari ukuran populasi yang lebih besar. Perhitungan Anda dari standar deviasi dan kesalahan standar akan jauh lebih akurat jika semua sampel berukuran sama.
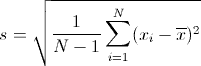
Seperti yang Anda lihat, ada beberapa variabel yang diperlukan untuk menemukan standar deviasi sampel. Kecuali Anda sudah mendefinisikan semuanya, masing-masing akan memerlukan beberapa perhitungan lebih lanjut. Semuanya didefinisikan di bawah:
- s: Standar deviasi sampel
- x1-xn: Data sampel terpisah menetapkan bahwa Anda menghitung, untuk menentukan standar deviasi sampel
- x̄: Nilai rata-rata yang diambil dari kumpulan data sampel
- N: Ukuran kumpulan data sampel, diambil dari populasi
Dengan menggunakan rumus ini, Anda akan dapat berhasil menentukan kesalahan standar atau ukuran sampel Anda, terkait dengan populasi. Ini adalah latihan yang cukup standar dalam ilmu statistik dan penelitian umum, setiap kali ada perbedaan antara beberapa sampel berbeda dan populasi yang ingin mereka wakili. Tentu saja, kami telah menjelaskan prosesnya selepat mungkin. Ada beberapa keadaan yang berbeda di mana formula bisa menjadi lebih kompleks. Misalnya, menentukan parameter dalam standar deviasi dapat menjadi sangat berbeda ketika Anda bekerja dengan banyak sampel berbeda; semakin banyak sampel yang Anda kerjakan, formula Anda akan semakin kompleks.
Namun, rumus di atas memang memungkinkan berbagai sampel berbeda untuk dimasukkan, terlepas dari ukuran atau kompleksitasnya. Jika Anda ingin membaca lebih lanjut tentang topik ini, lihat tautan yang kami berikan di bagian atas bagian ini.
Orang mungkin berpendapat bahwa jenis formula dan perhitungan ini hanya berguna bagi mereka yang berkomitmen untuk pengetahuan statistik yang rumit, tetapi Anda akan terkejut dengan betapa serbagunanya data tersebut. Ilmuwan penelitian dan bahkan jurnalis yang tertarik untuk mengukur tren naik dan tenggelam dapat memanfaatkan kesalahan standar dan standar deviasi. Ini dapat mengungkapkan hal-hal menarik tentang populasi dan sampel yang berasal dari mereka; jadi, jika profesi Anda bekerja secara teratur dengan sampel dan populasi, akan sangat membantu untuk menjaga formula ini tetap dekat.
Dengan menggunakan langkah-langkah di atas, Anda akan dapat mengetahui cara menghitung kesalahan standar dari sampel khusus studi Anda. Tidak hanya itu, tetapi Anda akan dapat menghitung standar deviasi yang diperlukan untuk yang pertama rumus. Jika Anda memiliki pertanyaan tentang salah satu dari ini, jangan ragu untuk menghubungi kami di bagian komentar di artikel ini! Kalau tidak, pertimbangkan untuk mengklik beberapa tautan terverifikasi yang kami berikan, untuk bacaan lebih lanjut.



