
Hot Chips 31 Live Blogs: Prosesor Pembelajaran Jauh Transistor 1.2 Triliun Cerebras

08:49 EDT – Beberapa berita besar hari ini adalah Cerebras mengumumkan solusi transistor 1,2 triliun wafer-nya untuk pembelajaran yang mendalam. Pembicaraan hari ini membahas detail tentang teknologi.
08:51 EDT – Chip skala wafer, lebih dari 46.225 mm2, 1,2 triliun transistor, 400k core AI, diumpankan oleh SRAM on-chip 18GB

08:51 EDT – TSMC 16nm
08:51 EDT – 215mm x 215mm – 8,5 inci per sisi
08:51 EDT – 56 kali lebih besar dari GPU terbesar saat ini
08:52 EDT – Dibangun untuk Pembelajaran Mendalam
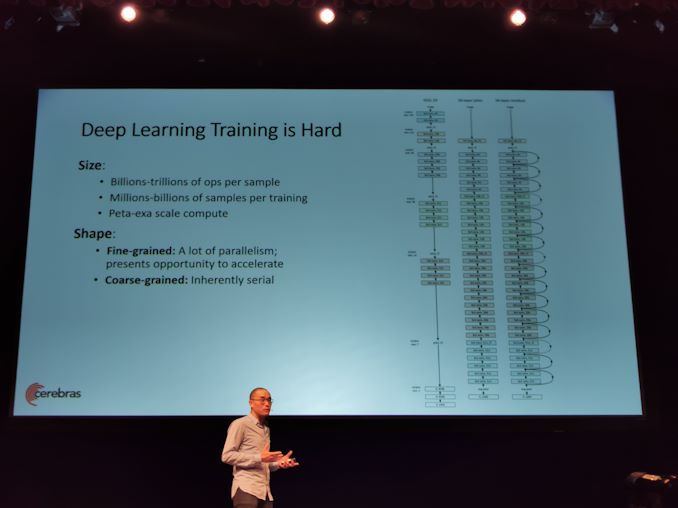
08:52 EDT – Pelatihan DL sulit (ed: ini adalah pernyataan yang meremehkan)

08:52 EDT – Rentang penghitungan skala Peta-ke-exa
08:53 EDT – Bentuk masalah sulit untuk diukur
08:53 EDT – Butir halus memiliki banyak paralelisme
08:53 EDT – Butir kasar pada dasarnya serial
08:53 EDT – Pelatihan adalah proses menerapkan perubahan kecil, secara serial
08:53 EDT – Ukuran dan bentuk masalah membuat pelatihan NN sangat sulit

08:53 EDT – Hari ini kita memiliki komputasi vektor yang padat
20:54 EDT – Untuk Butir Kasar, memerlukan interkoneksi kecepatan tinggi untuk menjalankan instance mutliple. Masih terbatas
20:54 EDT – Penskalaan terbatas dan mahal
20:54 EDT – Akselerator khusus adalah jawabannya

08.55 EDT – NN: apa arsitektur yang tepat
08.55 EDT – Perlu inti untuk dioptimalkan untuk primitif NN

08.55 EDT – Perlu inti NN yang dapat diprogram
08.55 EDT – Perlu melakukan komputasi cepat jarang
08.55 EDT – Membutuhkan memori lokal yang cepat
08.55 EDT – Semua core harus terhubung dengan interkoneksi cepat
08:56 EDT – Cerebras menggunakan inti fleksibel. Operasi umum yang fleksibel untuk pemrosesan kontrol

08:56 EDT – Core harus menangani operasi tensor dengan sangat efisien
08:56 EDT – Membentuk bulk untuk komputasi dalam jaringan saraf apa pun
08:56 EDT – Tensor sebagai operan kelas satu
08:57 EDT – op asli fmac
08:57 EDT – NN secara alami membuat jaringan yang jarang

08:58 EDT – Core memiliki pemrosesan jarang asli di perangkat keras dengan penjadwalan aliran data
08:58 EDT – Semua perhitungan dipicu oleh data
08:58 EDT – Memfilter semua nol jarang, dan menyaring pekerjaan
08:58 EDT – Menghemat daya dan energi, dan mendapatkan kinerja dan akselerasi dengan beralih ke pekerjaan berguna berikutnya
08:58 EDT – Diaktifkan karena arch memiliki datapaths eksekusi yang halus
08:58 EDT – Banyak core kecil dengan instruksi independen
08:59 EDT – Memungkinkan untuk pekerjaan yang sangat tidak seragam
08:59 EDT – Selanjutnya adalah memori

08:59 EDT – Arsitektur memori tradisional tidak dioptimalkan untuk DL
08:59 EDT – Memori tradisional membutuhkan penggunaan kembali data yang tinggi untuk performane
09:00 EDT – Multiply matriks normal memiliki penggunaan kembali data low-end
09:00 EDT – Menerjemahkan Mat * Vec ke Mat * Mat, tetapi mengubah dinamika pelatihan
09:00 EDT – Cerebras memiliki SRAM on-chip berdistribusi tinggi dan terdistribusi penuh di sebelah core
09:01 EDT – Menerima pesanan bandwidth yang lebih besar

09:01 EDT – ML dapat dilakukan dengan cara yang ingin dilakukan
09:01 EDT – Bandwidth tinggi, interkoneksi latensi rendah

09:01 EDT – fabric cepat dan sepenuhnya dapat dikonfigurasi
09:01 EDT – semua komunikasi berbasis hw avoicd sw overhead
09:02 PM EDT – Topologi mesh 2D
09:02 PM EDT – Penggunaan dan efisiensi yang lebih tinggi daripada topologi global
09:02 PM EDT – Perlu lebih dari satu mati
09:02 PM EDT – Solition adalah skala wafer
09:03 PM EDT – Bangun chip besar
09:03 PM EDT – Skala skala cluster pada satu chip

09:03 PM EDT – GB memori cepat (SRAM) 1 siklus clock dari inti
09:03 PM EDT – Itu tidak mungkin dengan memori off-chip
09:03 PM EDT – Kain interkoneksi penuh pada chip
09:03 PM EDT – Model paralel, penskalaan kinerja linier
09:04 PM EDT – Memetakan seluruh jaringan saraf ke chip sekaligus
09:04 PM EDT – Satu contoh NN, tidak harus menambah ukuran batch untuk mendapatkan perf skala cluster
09:04 PM EDT – Daya yang sangat rendah dan lebih sedikit ruang

09:04 PM EDT – Dapat menggunakan TensorFlow dan PyTorch
09:05 EDT – Melakukan penempatan dan perutean untuk memetakan lapisan jaringan saraf ke fabric
09:05 EDT – Seluruh wafer beroperasi pada jaringan saraf tunggal
09:05 EDT – Tantangan skala wafer
09:05 EDT – Perlu konektivitas cross-die, hasil, ekspansi termal


09:06 PM EDT – Garis juru tulis memisahkan dadu. Di atas garis juru tulis, buat kabel
09:07 PM EDT – Memperluas kain jala 2D di semua die
09:07 PM EDT – Konektivitas yang sama antara core dan antara die
09:07 PM EDT – Lebih efisien daripada off-chip

09:07 PM EDT – BW penuh di tingkat mati
09:08 PM EDT – Redundansi membantu menghasilkan

09:08 PM EDT – Core redundan dan tautan fabric redundan
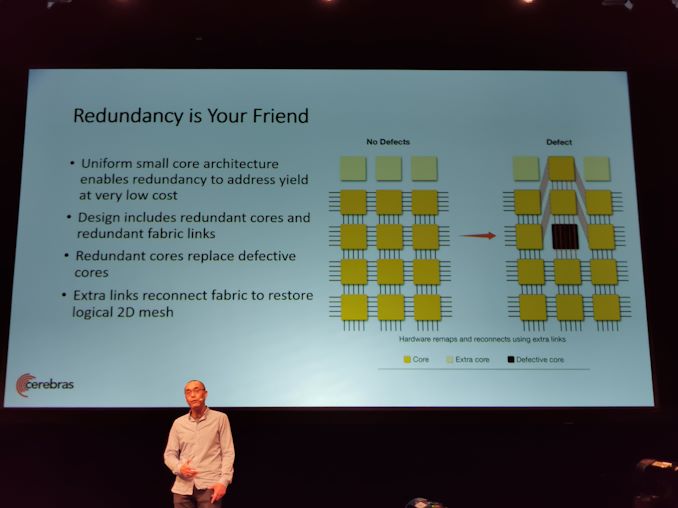
09:08 PM EDT – Hubungkan kembali fabric dengan tautan
09:08 PM EDT – Drive hasil tinggi
09:09 PM EDT – Transparan ke perangkat lunak
09:09 PM EDT – Ekspansi termal

09:09 PM EDT – Teknologi normal, terlalu banyak tekanan mekanis melalui ekspansi termal
09:09 PM EDT – Konektor khusus dikembangkan
09:09 PM EDT – Konektor menyerap variasi ekspansi termal

09:10 EDT – Semua komponen harus dipegang dengan perataan yang tepat – alat pengemasan khusus

09:10 EDT – Daya dan Pendinginan

09:11 EDT – Pesawat listrik tidak berfungsi – tidak cukup tembaga di PCB untuk melakukannya dengan cara itu
09:11 EDT – Kepadatan panas terlalu tinggi untuk pendinginan udara langsung
09:12 PM EDT – Bawa arus tegak lurus ke wafer. Air juga didinginkan secara tegak lurus


09:14 EDT – Waktu Tanya Jawab

09:14 EDT – Q dan A
09:14 EDT – Telah digunakan? iya nih
09:15 EDT – Bisakah Anda membuat chip bundar? Kotak lebih nyaman
09:15 EDT – Hasil? Proses matang cukup baik dan seragam
09:16 PM EDT – Apakah harganya lebih murah dari sebuah rumah? Semuanya diamortisasi di seluruh wafer
09:17 PM EDT – Prosesor rutin untuk tata graha? Mereka semua bisa melakukannya
09:17 PM EDT – Apakah sepenuhnya sinkron? Tidak
09.20 EDT – Kecepatan clock? Tidak diungkapkan
09.20 EDT – Itu bungkus. Berikutnya adalah Habana


![[Actualizado] Huawei mulai beriklan di wallpaper lanskap yang sudah diinstal pada komputer mereka](../wp-content/uploads/2019/09/Actualizado-Huawei-mulai-beriklan-di-wallpaper-lanskap-yang-sudah-diinstal.png)

