
Intel Cascade Lake Dengan DL Boost Goes Head to Head dengan Titan RTX Nvidia dalam Tes AI

Situs ini dapat memperoleh komisi afiliasi dari tautan di halaman ini. Syarat Penggunaan. 
Selama beberapa tahun terakhir, Intel telah membicarakan server Cascade Lake dengan DL Boost (juga dikenal sebagai VNNI, Petunjuk Neural Net Vector). Kemampuan baru ini adalah bagian dari AVX-512 dan dimaksudkan untuk secara khusus mempercepat kinerja CPU dalam aplikasi AI. Secara historis, banyak aplikasi AI lebih menyukai GPU daripada CPU. Arsitektur GPU – prosesor paralel besar-besaran dengan kinerja single-thread rendah – lebih cocok untuk prosesor grafis daripada CPU. CPU menawarkan lebih banyak sumber daya eksekusi per utas, tetapi bahkan CPU multi-core saat ini dikerdilkan oleh paralelisme yang tersedia dalam inti GPU kelas atas.
Anandtech telah membandingkan kinerja Cascade Lake, Epyc 7601 (segera akan dilampaui oleh CPU Roma 7nm AMD, tetapi masih inti server AMD terkemuka hari ini), dan sebuah RTX Titan. Artikel tersebut, oleh Johan De Gelas yang sangat baik, membahas berbagai jenis jaring saraf di luar CNN (Convolutional Neural Networks) yang biasanya diperbandingkan, dan bagaimana bagian penting dari strategi Intel bersaing dengan Nvidia dalam beban kerja di mana GPU tidak sekuat atau belum dapat memenuhi kebutuhan pasar yang muncul karena keterbatasan kapasitas memori (GPU masih belum bisa menandingi CPU di sini), penggunaan model AI 'ringan' yang tidak memerlukan waktu pelatihan yang lama, atau model AI yang bergantung pada model statistik jaringan non-neural.
Pendapatan pusat data yang berkembang adalah komponen penting dari dorongan keseluruhan Intel ke dalam AI dan pembelajaran mesin. Nvidia, sementara itu, ingin melindungi pasar yang saat ini bersaing di hampir sendirian. Strategi AI Intel luas dan mencakup banyak produk, dari Movidius dan Nervana hingga DL Boost di Xeon, hingga lini Xe GPU yang akan datang. Nvidia berusaha menunjukkan bahwa GPU dapat digunakan untuk menangani perhitungan AI dalam rentang beban kerja yang lebih luas. Intel sedang membangun kemampuan AI baru ke dalam produk yang sudah ada, menerjunkan perangkat keras baru yang diharapkan akan berdampak pada pasar, dan mencoba membangun GPU serius pertamanya untuk menantang pekerjaan yang dilakukan AMD dan Nvidia di seluruh ruang konsumen.
Apa yang menunjukkan tolok ukur Anandtech, secara agregat, adalah bahwa jurang antara Intel dan Nvidia tetap lebar – bahkan dengan DL Boost. Grafik ini dari tes Jaringan Berulang Recurrent menggunakan jaringan "Memori Jangka Pendek (LSTM) sebagai jaringan saraf. Suatu jenis RNN, LSTM secara selektif “mengingat” pola selama durasi waktu tertentu. ”Anandtech juga menggunakan tiga konfigurasi berbeda untuk mengujinya – Tensorflow dengan konda yang tidak sesuai, dengan Tensorflow yang dioptimalkan oleh Intel dengan PyPi, dan sebuah versi Tensorflow dioptimalkan dari sumber menggunakan Bazel, menggunakan versi terbaru Tensorflow.
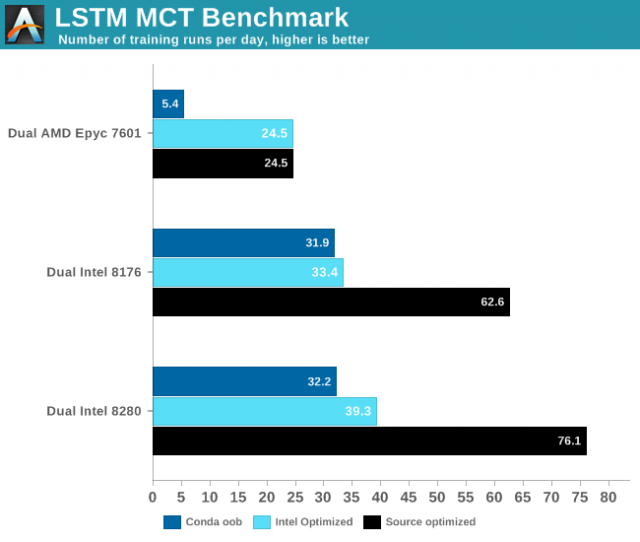
Gambar oleh Anandtech
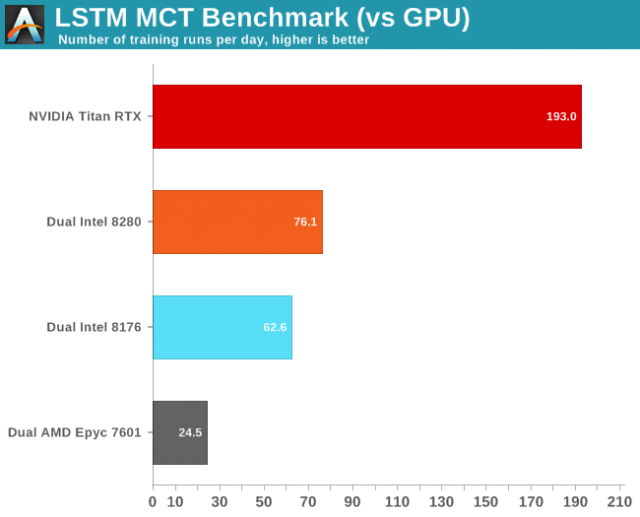
Gambar oleh Anandtech
Pasangan gambar ini menangkap skala relatif antara CPU dan juga perbandingannya dengan RTX Titan. Kinerja out of the box cukup buruk pada AMD, meskipun ditingkatkan dengan kode yang dioptimalkan. Kinerja Intel melonjak seperti roket ketika versi yang dioptimalkan sumber diuji, tetapi bahkan versi yang dioptimalkan sumber tidak cocok dengan kinerja Titan RTX dengan sangat baik. De Gelas mencatat: "Kedua, kami cukup kagum bahwa Titan RTX kami kurang dari 3 kali lebih cepat dari pengaturan dual Xeon kami," yang memberi tahu Anda tentang bagaimana perbandingan ini berjalan dalam artikel yang lebih besar.
DL Boost tidak cukup untuk menutup kesenjangan antara Intel dan Nvidia, tetapi dalam keadilan, mungkin tidak pernah seharusnya demikian. Tujuan Intel di sini adalah untuk meningkatkan kinerja AI cukup pada Xeon untuk membuat menjalankan beban kerja ini masuk akal di server yang sebagian besar akan digunakan untuk hal-hal lain, atau ketika membangun model AI yang tidak sesuai dengan kendala GPU modern. Tujuan jangka panjang perusahaan adalah untuk bersaing di pasar AI dengan berbagai peralatan, bukan hanya Xeon. Dengan Xe belum siap, bersaing di ruang HPC sekarang berarti bersaing dengan Xeon.
Bagi Anda yang bertanya-tanya tentang AMD, AMD tidak benar-benar berbicara tentang menjalankan beban kerja AI pada Epyc CPU, tetapi berfokus pada inisiatif RocM untuk menjalankan kode CUDA pada OpenCL. AMD tidak banyak membicarakan sisi bisnisnya ini, tetapi Nvidia mendominasi pasar untuk aplikasi GPU AI dan HPC. Baik AMD dan Intel menginginkan ruang. Saat ini, keduanya tampaknya berjuang keras untuk mengklaim satu.
Sekarang baca:




