
Nvidia Meluncurkan Teknologi AI Percakapan untuk Bot yang Lebih Cerdas

Situs ini dapat memperoleh komisi afiliasi dari tautan di halaman ini. Syarat Penggunaan. 
Sekarang, karena hampir setiap perangkat dan perangkat seluler yang mungkin telah mengadopsi atau setidaknya bereksperimen dengan kontrol suara, AI percakapan dengan cepat menjadi perbatasan baru. Alih-alih menangani satu permintaan dan memberikan satu respons atau tindakan, AI percakapan bertujuan untuk menyediakan sistem interaktif waktu nyata yang dapat menjangkau beberapa pertanyaan, jawaban, dan komentar. Sementara dasar penyusun AI percakapan, seperti BERT dan RoBERTa untuk pemodelan bahasa, serupa dengan yang untuk pengenalan suara satu-jepretan, konsep ini dilengkapi dengan persyaratan kinerja tambahan untuk pelatihan, menyimpulkan, dan ukuran model. Hari ini, Nvidia merilis dan open-source tiga teknologi yang dirancang untuk mengatasi masalah tersebut.
Pelatihan BERT yang lebih cepat
 Meskipun dalam banyak kasus dimungkinkan untuk menggunakan model bahasa pra-terlatih untuk tugas-tugas baru hanya dengan penyetelan, untuk kinerja yang optimal dalam konteks tertentu pelatihan ulang adalah suatu keharusan. Nvidia telah menunjukkan bahwa ia sekarang dapat melatih BERT (model bahasa referensi Google) dalam waktu kurang dari satu jam pada DGX SuperPOD yang terdiri dari 1.472 Tesla V100-SXM3-32GB GPU, 92 server DGX-2H, dan 10 Mellanox Infiniband per node. Tidak, saya bahkan tidak ingin mencoba dan memperkirakan biaya sewa per jam untuk salah satunya. Tetapi karena model seperti ini biasanya membutuhkan waktu berhari-hari untuk melatih bahkan pada kluster GPU kelas atas, ini pasti akan membantu waktu untuk memasarkan perusahaan yang mampu membayar biayanya.
Meskipun dalam banyak kasus dimungkinkan untuk menggunakan model bahasa pra-terlatih untuk tugas-tugas baru hanya dengan penyetelan, untuk kinerja yang optimal dalam konteks tertentu pelatihan ulang adalah suatu keharusan. Nvidia telah menunjukkan bahwa ia sekarang dapat melatih BERT (model bahasa referensi Google) dalam waktu kurang dari satu jam pada DGX SuperPOD yang terdiri dari 1.472 Tesla V100-SXM3-32GB GPU, 92 server DGX-2H, dan 10 Mellanox Infiniband per node. Tidak, saya bahkan tidak ingin mencoba dan memperkirakan biaya sewa per jam untuk salah satunya. Tetapi karena model seperti ini biasanya membutuhkan waktu berhari-hari untuk melatih bahkan pada kluster GPU kelas atas, ini pasti akan membantu waktu untuk memasarkan perusahaan yang mampu membayar biayanya.
Inferensi Model Bahasa Lebih Cepat
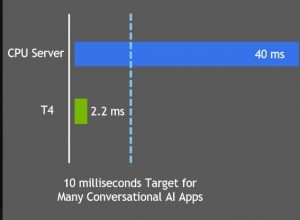
Untuk percakapan alami, tolok ukur industri adalah waktu respons 10 ms. Memahami kueri dan memberikan jawaban yang disarankan hanyalah salah satu bagian dari proses, sehingga perlu waktu kurang dari 10 ms. Dengan mengoptimalkan BERT menggunakan TensorRT 5.1, Nvidia memilikinya menyimpulkan dalam 2.2ms pada Nvidia T4. Apa yang keren adalah bahwa T4 sebenarnya berada dalam jangkauan hampir semua proyek serius. Saya menggunakannya di Google Compute Cloud untuk sistem pembuatan teks saya. Server virtual 4-vCPU dengan T4 disewa hanya lebih dari $ 1 / jam ketika saya melakukan proyek.
Dukungan untuk Model yang Lebih Besar
 Salah satu Tumit jaringan saraf Achilles adalah persyaratan bahwa semua parameter model (termasuk sejumlah besar bobot) harus ada dalam memori sekaligus. Itu membatasi kompleksitas model yang dapat dilatih pada GPU dengan ukuran RAM-nya. Dalam kasus saya, misalnya, desktop saya Nvidia GTX 1080
Salah satu Tumit jaringan saraf Achilles adalah persyaratan bahwa semua parameter model (termasuk sejumlah besar bobot) harus ada dalam memori sekaligus. Itu membatasi kompleksitas model yang dapat dilatih pada GPU dengan ukuran RAM-nya. Dalam kasus saya, misalnya, desktop saya Nvidia GTX 1080![]() hanya dapat melatih model yang sesuai dengan 8GB-nya. Saya dapat melatih model yang lebih besar pada CPU saya, yang memiliki lebih banyak RAM, tetapi membutuhkan waktu lebih lama. Model bahasa GPT-2 lengkap memiliki 1,5 miliar parameter, misalnya, dan versi yang diperluas memiliki 8,3 miliar.
hanya dapat melatih model yang sesuai dengan 8GB-nya. Saya dapat melatih model yang lebih besar pada CPU saya, yang memiliki lebih banyak RAM, tetapi membutuhkan waktu lebih lama. Model bahasa GPT-2 lengkap memiliki 1,5 miliar parameter, misalnya, dan versi yang diperluas memiliki 8,3 miliar.
Nvidia, bagaimanapun, telah datang dengan cara untuk memungkinkan beberapa GPU bekerja pada tugas pemodelan bahasa secara paralel. Seperti pengumuman lainnya hari ini, mereka telah membuka kode sumber untuk mewujudkannya. Saya akan sangat ingin tahu apakah teknik ini khusus untuk model bahasa atau dapat diterapkan untuk memungkinkan pelatihan multi-GPU untuk kelas-kelas lain dari jaringan saraf.
Seiring dengan perkembangan ini dan merilis kode pada GitHub, Nvidia mengumumkan bahwa mereka akan bermitra dengan Microsoft untuk meningkatkan hasil pencarian Bing, serta dengan Clinc pada agen suara, Passage AI di chatbots, dan RecordSure pada analitik percakapan.
Sekarang baca:




